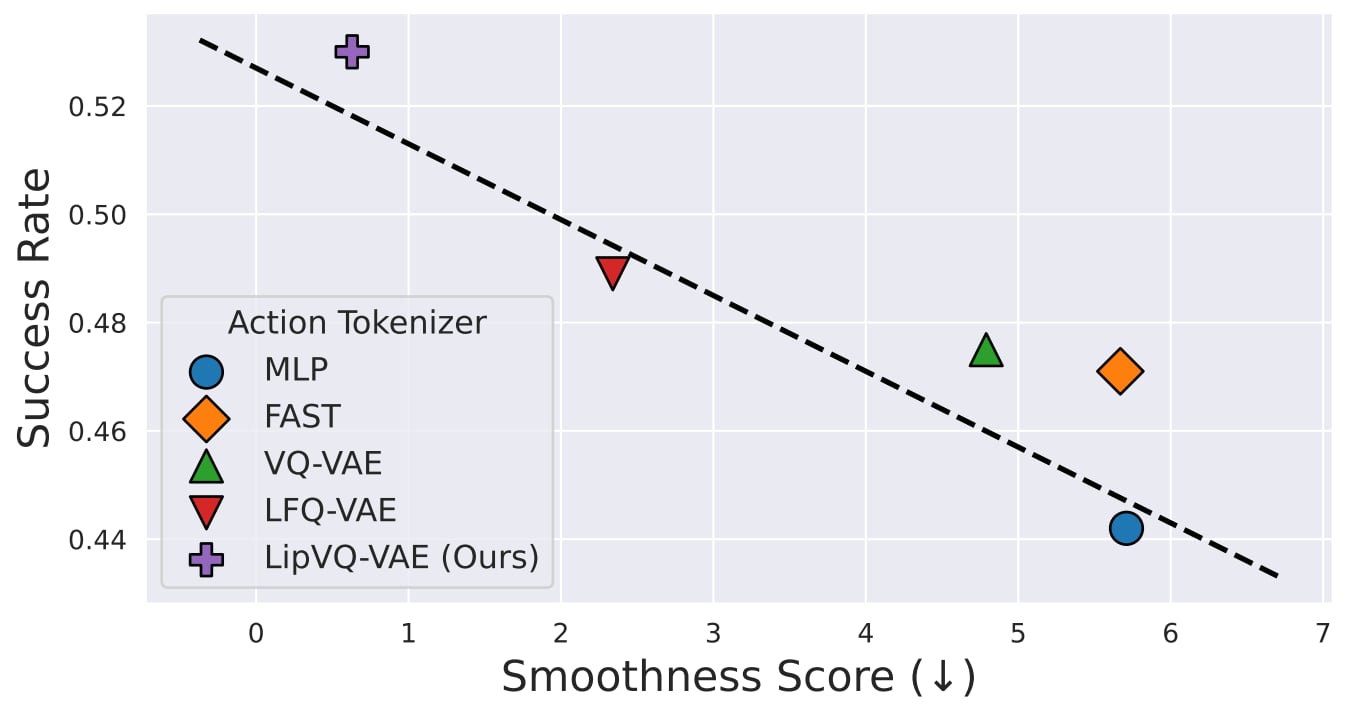
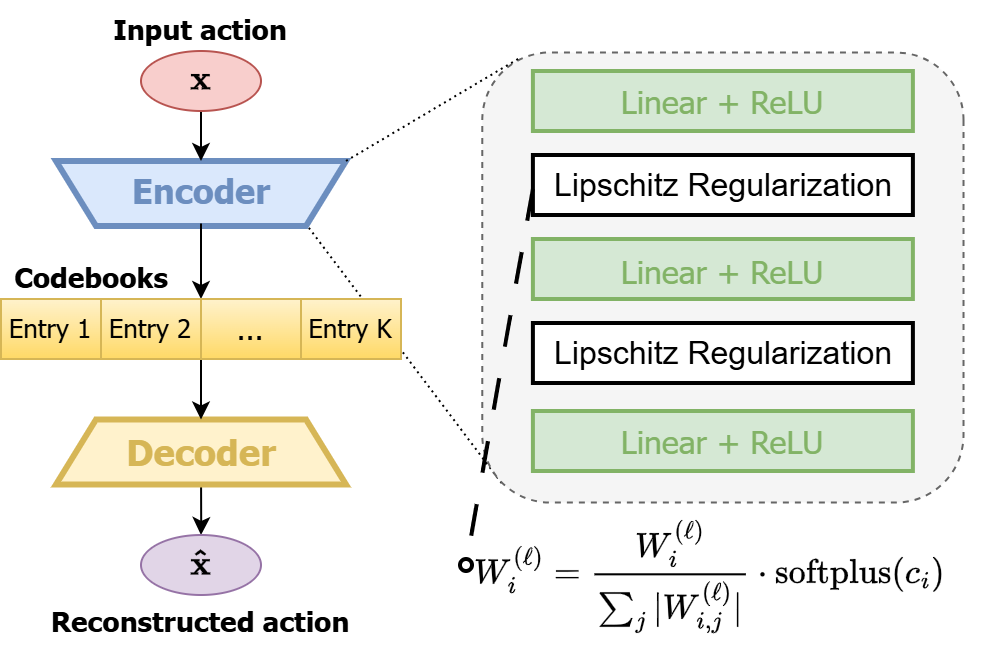
In-context imitation learning (ICIL) is a new paradigm that enables robots to generalize from demonstrations to unseen tasks without retraining. A well-structured action representation is the key to capturing demonstration information effectively, yet action tokenizer (the process of discretizing and encoding actions) remains largely unexplored in ICIL. In this work, we first systematically evaluate existing action tokenizer methods in ICIL and reveal a critical limitation: while they effectively encode action trajectories, they fail to preserve temporal smoothness, which is crucial for stable robotic execution. To address this, we propose LipVQ-VAE, a variational autoencoder that enforces the Lipschitz condition in the latent action space via weight normalization. By propagating smoothness constraints from raw action inputs to a quantized latent codebook, LipVQ-VAE generates more stable and smoother actions. When integrating into ICIL, LipVQ-VAE improves performance by more than 5.3% in high-fidelity simulators, with real-world experiments confirming its ability to produce smoother, more reliable trajectories.